#include <stdio.h>
#include <stdbool.h>
#include <malloc.h>
#define H malloc (1237) ;
#define c while
#define W >> /* fallen right tree */
#define w << /* fallen left tree */
#define B(wish,times) ((_ &wish) times 2)
#define L {o Q=q;p(3[Z]),P(false[Z],q),\
p(q>2?"th":N),p(Z[2]);c(true+Q)p(q|Q?Q?\
N:4[Z]:"a "),P(1[Z],Q),p(Q>1?", ":N),--\
Q;p(".\n\n"),++q;}
char typedef o;void typedef d
;
o*N
="";o
q;o*O(o
*p){o
*P,_;o*
f=P=H;c(_
=*p)_^=1,*f
++=B(1,w)|B(4
,W)|B(2,w)|
B(8,W)|(_&240
),++p,*f=false;
return P;}d p(o*f
){fputs(f,stdout);}
d P(o*s,o o){c( o
--){c(122-*s)s++; s
++;}c(122-*s)putchar(
*s++);} o main(void){o*
Z[]={O("hgy}p{}dmnj`{pcg"
"y`{hny{hgh{}gs{}dxdj{"
"dglc{jgj{pdj{dbdxdj{p|d"
"bh{"),O("qeypyg`ld!gj!e!q"
"dey!pydd{p|n!ptypbd!`nxd}{p"
"cydd!Hydjmc!Cdj}{hnty!mnbbw!i"
"gy`"
"}{h"
"gxd"
"!ln"
"b`d"
"j!ygjl}{}gs!ldd}"
"d&e&bewgjl{}dxdj"
"!}|ej}&e&}|gff"
"gjl{dglcp!feg`"
"}&e&fgbogjl{jgjd!be`gd}!`ejmgjl{pdj!bny`}&e&bdeqgjl{"
"dbdxdj!qgqdy}&qgqgjl{p|dbxd!`ytffdy}!`ytffgjl{") ,O (
"!`ew!nh!Mcyg}pfe}!fw!pytd!bnxd!lexd!pn!fd!"),O("Nj!p"
"cd!"),O("!ej`!e!")};L L L L L L L L L L L L /*Xmas*/}
Wednesday, 19 December 2012
..and now something seasonal
The Christmas holidays are almost here and to celebrate I've mildly obfuscated some C that prints the lyrics to a traditional English carol.
The source code can be found here
Saturday, 15 December 2012
Debugging using Visualisation.
There are many different classes of bugs and hence many different debugging techniques can be used. Sometimes there is a lot of complexity in a problem and it is hard to make a mental model of what exactly is going on between multiple interdependent components, especially when non-deterministic behaviour is occurring.
Unfortunately the human mind is limited; there is only so much debugging state that it can follow. The problem is compounded when a bug manifests itself after several hours or days of continuous execution time - there just seems like there is too much state to track and to make sense from.
Looking at thousands of lines of debug trace and trying to spot any lurking evidence that may offer some hint to why code is failing is not trivial. However the brain is highly developed at making sense of visual input, so it makes sense to visualise copious amounts of debug data to spot anomalies.
The kernel offers many ways to gather data, be it via different trace mechanisms or just by using plain old printk(). The steps to debug are thus:
1. Try and find a way to reliably reproduce the problem to be debugged.
2. Where possible, try to remove complexity from the problem and still end up with a reliable way of reproducing the problem.
3. Rig up a way of collecting internal state or data on system activity. Obviously the type of data to be collected is dependant on the type of problem being worked on. Be careful that any instrumentation does not affect the behaviour of the system.
4. Start collecting data and try to reproduce the bug. You may have to do this multiple times to collect enough data to allow one to easily spot trends over different runs.
5. Visualise the data.
Iterating on steps 2 to 5 allow one to keep on refining a problem down to the bare minimum required to corner a bug.
Now step 5 is the fun part. Sometimes one has to lightly parse the output to collect specific items of data. I generally use tools such as awk to extract specific fields or to re-munge data into a format that can be easily processed by graphing tools. It can be useful to also collect time stamps with the data as some bugs are timing dependant and seeing interactions between components is key to understanding why issues occur. If one gathers multiple sets of data from different sources then being able to correlate the data on a timestamp can be helpful.
If I have just a few tens of hundreds items of data to visualise I generally just collate my data into tab or comma separated output and then import it into LibreOffice Calc and then generate graphs from the raw data. However, for more demanding graphing I normally resort to using gnuplot. Gnuplot is an incredibly powerful plotting tool - however for more complex graphs one often needs to delve deep into the manual and perhaps crib from the very useful worked examples.
Graphing data allows one to easily spot trends or correlate between seemingly unrelated parts of a system. What was originally an overwhelmingly huge mass of debug data turns into a powerful resource. Sometimes I find it useful to run multiple tests over a range of tweaked kernel tuneables to see if bugs change behaviour - often this aids understanding when there is significant amounts of inter-component complexity occurring.
Perhaps it is just the way I like to think about issues, but I do recommend experimenting with collecting large data sets and creatively transforming the data into visualise representations to allow one to easily spot issues. It can be surprising just how much one can glean from thousands of seemingly unrelated traces of debug data.
Unfortunately the human mind is limited; there is only so much debugging state that it can follow. The problem is compounded when a bug manifests itself after several hours or days of continuous execution time - there just seems like there is too much state to track and to make sense from.
Looking at thousands of lines of debug trace and trying to spot any lurking evidence that may offer some hint to why code is failing is not trivial. However the brain is highly developed at making sense of visual input, so it makes sense to visualise copious amounts of debug data to spot anomalies.
The kernel offers many ways to gather data, be it via different trace mechanisms or just by using plain old printk(). The steps to debug are thus:
1. Try and find a way to reliably reproduce the problem to be debugged.
2. Where possible, try to remove complexity from the problem and still end up with a reliable way of reproducing the problem.
3. Rig up a way of collecting internal state or data on system activity. Obviously the type of data to be collected is dependant on the type of problem being worked on. Be careful that any instrumentation does not affect the behaviour of the system.
4. Start collecting data and try to reproduce the bug. You may have to do this multiple times to collect enough data to allow one to easily spot trends over different runs.
5. Visualise the data.
Iterating on steps 2 to 5 allow one to keep on refining a problem down to the bare minimum required to corner a bug.
Now step 5 is the fun part. Sometimes one has to lightly parse the output to collect specific items of data. I generally use tools such as awk to extract specific fields or to re-munge data into a format that can be easily processed by graphing tools. It can be useful to also collect time stamps with the data as some bugs are timing dependant and seeing interactions between components is key to understanding why issues occur. If one gathers multiple sets of data from different sources then being able to correlate the data on a timestamp can be helpful.
If I have just a few tens of hundreds items of data to visualise I generally just collate my data into tab or comma separated output and then import it into LibreOffice Calc and then generate graphs from the raw data. However, for more demanding graphing I normally resort to using gnuplot. Gnuplot is an incredibly powerful plotting tool - however for more complex graphs one often needs to delve deep into the manual and perhaps crib from the very useful worked examples.
Graphing data allows one to easily spot trends or correlate between seemingly unrelated parts of a system. What was originally an overwhelmingly huge mass of debug data turns into a powerful resource. Sometimes I find it useful to run multiple tests over a range of tweaked kernel tuneables to see if bugs change behaviour - often this aids understanding when there is significant amounts of inter-component complexity occurring.
Perhaps it is just the way I like to think about issues, but I do recommend experimenting with collecting large data sets and creatively transforming the data into visualise representations to allow one to easily spot issues. It can be surprising just how much one can glean from thousands of seemingly unrelated traces of debug data.
Saturday, 1 December 2012
UNIX 1st Edition restoration project.
Earlier this week I stumbled upon the unix-jun72 project which is a restoration of the 1st edition of UNIX based on a scanned printout of the original source. Unfortunately not all the source is available, but some userland binaries and the C compiler have been recovered from some tapes and there is enough functionality to be able to boot to a minimal and usable system.
The first step is to download and build the most excellent Simh simulator so that we can simulate a PDP-11. Fortunately the disk images are already pre-built and downloadable, so one just has to download these and point the PDP-11 simulator at a config file and the system almost instantly boots. The full instructions are provided in great detail here.
I am rather fond of the PDP-11. It was the first mini computer I worked on back in 1987 when I was a very junior programmer at Prosig. The machine was running RSX-11M Plus rather than UNIX but even so it gave me the appreciation of what one can do on a very small multi-user machine. At the time I was maintaining, building and testing DATS signal processing tools written in Fortran 77, and some of the work involved tinkering with task builder scripts to try and cram code into the very limited memory.
So in those days size really mattered. Small was considered beautiful and this mindset was instilled into me in my formative years. So I was very pleased to find the unix-jun72 project which allows me to relive those PDP-11 days and also experience UNIX-1.
Since some of the original source code still exists, one can browse the source of the kernel and some of the core utilities. It is amazing to see the functionality that is available in very small binaries.
Let's fire up the simulator and see the size of the 'cat' command:
And how does that compare to a GNU cat on a 64 bit Ubuntu laptop?
134 bytes versus 47912 bytes. That is quite a difference! Admittedly we are comparing apples vs pears here, so obviously this is an unfair comparison, but it does illustrate how we've "progressed" since the early UNIX-1 days. Honestly I'm glad we can now write userland tools and the kernel in C rather than assembler and not have to worry about size constraints quite so much.
I'm very glad that this project exists to preserve the UNIX heritage. History has a lot to teach us. Browsing the early code is an education; it allows us to appreciate the memory constraints that shaped the design and implementation of UNIX. To be able to run this code in a simulator and tinker with a running system adds to the experience.
We've moved on a long way in 40 or so years, machines are incredibly powerful, and memory and disk is cheap. But let us not forget the "small is beautiful" ideal. There is something very appealing about tools that do just enough to be very useful and yet are not bloated with unnecessary memory hogging feature creep.
The first step is to download and build the most excellent Simh simulator so that we can simulate a PDP-11. Fortunately the disk images are already pre-built and downloadable, so one just has to download these and point the PDP-11 simulator at a config file and the system almost instantly boots. The full instructions are provided in great detail here.
I am rather fond of the PDP-11. It was the first mini computer I worked on back in 1987 when I was a very junior programmer at Prosig. The machine was running RSX-11M Plus rather than UNIX but even so it gave me the appreciation of what one can do on a very small multi-user machine. At the time I was maintaining, building and testing DATS signal processing tools written in Fortran 77, and some of the work involved tinkering with task builder scripts to try and cram code into the very limited memory.
So in those days size really mattered. Small was considered beautiful and this mindset was instilled into me in my formative years. So I was very pleased to find the unix-jun72 project which allows me to relive those PDP-11 days and also experience UNIX-1.
Since some of the original source code still exists, one can browse the source of the kernel and some of the core utilities. It is amazing to see the functionality that is available in very small binaries.
Let's fire up the simulator and see the size of the 'cat' command:
PDP-11 simulator V3.9-0
Disabling CR
Disabling XQ
RF: buffering file in memory
TC0: 16b format, buffering file in memory
:login: root
root
# ls -al /bin/cat
total 1
50 sxrwr- 1 bin 134 Jan 1 00:00:00 cat
And how does that compare to a GNU cat on a 64 bit Ubuntu laptop?
ls -al /bin/cat
-rwxr-xr-x 1 root root 47912 Nov 28 12:48 /bin/cat
134 bytes versus 47912 bytes. That is quite a difference! Admittedly we are comparing apples vs pears here, so obviously this is an unfair comparison, but it does illustrate how we've "progressed" since the early UNIX-1 days. Honestly I'm glad we can now write userland tools and the kernel in C rather than assembler and not have to worry about size constraints quite so much.
I'm very glad that this project exists to preserve the UNIX heritage. History has a lot to teach us. Browsing the early code is an education; it allows us to appreciate the memory constraints that shaped the design and implementation of UNIX. To be able to run this code in a simulator and tinker with a running system adds to the experience.
We've moved on a long way in 40 or so years, machines are incredibly powerful, and memory and disk is cheap. But let us not forget the "small is beautiful" ideal. There is something very appealing about tools that do just enough to be very useful and yet are not bloated with unnecessary memory hogging feature creep.
Friday, 23 November 2012
Using the gcc cleanup attribute
Section 6.36 of the GCC manual describes the rather interesting cleanup variable attribute. This allows one to specify a function to call when the variable goes out of scope.
The caveat is that the cleanup attribute can only be used with auto function scope variables, so it cannot be used on function parameters or static variables.
So what about an simple example? How about automatic free'ing on variables that go out of scope? This way we can be lazy and do automatic garbage collecting without having to remember to free() each allocation. Now, I'm not recommending this is good practice, I am just using this as an example.
Below I define a macro autofree that we use on the auto variables that we want to garbage collect on. When the variable goes out of scope __autofree() is called and it is passing the address of the variable. GCC insists on the helper function to be passed as a pointer to the type of the variable being cleaned. To handle any particular type I used a void * argument __autofree() and then I cast this to a void ** to allow me to free the memory that the variable pointed to, so a little bit of legitimate slight of hand being used here.
In this example, I malloc memory for x and then y. Then y and then x go out of scope and the cleaner function __autofree() frees the memory in that order:
I'm sure there are other ways that this can be creatively used (or abused...); as it stands it is a GCC extension so it is not portable C in any shape or form.
The caveat is that the cleanup attribute can only be used with auto function scope variables, so it cannot be used on function parameters or static variables.
So what about an simple example? How about automatic free'ing on variables that go out of scope? This way we can be lazy and do automatic garbage collecting without having to remember to free() each allocation. Now, I'm not recommending this is good practice, I am just using this as an example.
Below I define a macro autofree that we use on the auto variables that we want to garbage collect on. When the variable goes out of scope __autofree() is called and it is passing the address of the variable. GCC insists on the helper function to be passed as a pointer to the type of the variable being cleaned. To handle any particular type I used a void * argument __autofree() and then I cast this to a void ** to allow me to free the memory that the variable pointed to, so a little bit of legitimate slight of hand being used here.
#include <stdlib.h>
#include <stdio.h>
#define autofree __attribute((cleanup(__autofree)))
void __autofree(void *p)
{
void **_p = (void**)p;
printf("free -> %p\n", *_p);
free(*_p);
}
void *myalloc(size_t sz)
{
void *ptr;
if ((ptr = malloc(sz)) == NULL) {
fprintf(stderr, "malloc failed.\n");
exit(1);
}
printf("malloc -> %p\n", ptr);
return ptr;
}
int main(int argc, char **argv)
{
autofree char *x = myalloc(32);
{
autofree int *y = myalloc(64);
printf("y = %p\n", y);
}
printf("x = %p\n", x);
return 0;
}
In this example, I malloc memory for x and then y. Then y and then x go out of scope and the cleaner function __autofree() frees the memory in that order:
malloc -> 0x1504010
malloc -> 0x1504040
y = 0x1504040
free -> 0x1504040
x = 0x1504010
free -> 0x1504010
I'm sure there are other ways that this can be creatively used (or abused...); as it stands it is a GCC extension so it is not portable C in any shape or form.
Saturday, 17 November 2012
Benford's Law with real world data.
If one has a large enough real life source of data (such as the size of files in the file system) and look at the distribution of the first digit of these values then one will find something that at first glance is rather surprising. The leading digit 1 appears about 30% of the time and as the digits increase to 9 their frequency drops until we reach 9, which only appears about 5% of the time. This seemingly curious frequency distribution is commonly known as Benford's law or the first digit law.
The probability P of digit d can be expresses as follows:
..where d is any integer value 1 to 9 inclusive. So for each leading digit in the data, the distribution works out to be about:
But how does this hold up with some "real world" data? Can it really be true? Well, for my first experiment, I analysed the leading digit of all the source files in the current Linux source tree and compared that to Benford's Law:

So, this is convincing enough. How about something more exotic? For my second experiment I counted up the number of comments in each file that start with /* in just the C source files in the Linux source tree and again looked at the distribution of the leading digits. I was hazarding a guess that there are a reasonable amount of comments in each file (knowing the way some code is commented this may be pushing my luck). Anyhow, the data generated also produces a distribution that obeys Benford's Law too:

Well, that certainly shows that Kernel developers are sprinkling enough comments in the Kernel source to be statistically meaningful. If the comments themselves are meaningful is another matter...
How about one more test? This time I gathered the length of every executable in /usr/bin and plotted the distribution of the leading digits from this data:

..this data set has far less files to analyse, so the distribution deviates a little, but the trend is still rather good.
As mentioned earlier, one has to have a large set of data for this too work well. Interesting this may be, but what kind of practical use is it? It can be applied to accountancy - if one has a large enough set of data in the accounts and the leading digits of the data do not fit Benford's Law then maybe one should suspect that somebody has been fiddling the books. Humans are rather poor at making up lots of "random" values that don't skew Benford's Law.
One more interesting fact is that it applies even if one rescales the data. For example, if you are looking at accounts in terms of £ sterling and covert it into US dollars or Albanian Lek the rescaled data still obeys Benford's Law. Thus if re-ran my tests and didn't analyse the size of files in bytes but instead used size in 512 byte blocks it still would produce a leading digit distribution that obeyed Benford's Law. Nice.
How can we apply this in computing? Perhaps we could use it to detect tampering with the sizes of a large set of files. Who knows? I am sure somebody can think of a useful way to use it. I just find it all rather fascinating.
The probability P of digit d can be expresses as follows:
P(d) = log10(1 + 1 / d)
..where d is any integer value 1 to 9 inclusive. So for each leading digit in the data, the distribution works out to be about:
But how does this hold up with some "real world" data? Can it really be true? Well, for my first experiment, I analysed the leading digit of all the source files in the current Linux source tree and compared that to Benford's Law:
So, this is convincing enough. How about something more exotic? For my second experiment I counted up the number of comments in each file that start with /* in just the C source files in the Linux source tree and again looked at the distribution of the leading digits. I was hazarding a guess that there are a reasonable amount of comments in each file (knowing the way some code is commented this may be pushing my luck). Anyhow, the data generated also produces a distribution that obeys Benford's Law too:
Well, that certainly shows that Kernel developers are sprinkling enough comments in the Kernel source to be statistically meaningful. If the comments themselves are meaningful is another matter...
How about one more test? This time I gathered the length of every executable in /usr/bin and plotted the distribution of the leading digits from this data:
..this data set has far less files to analyse, so the distribution deviates a little, but the trend is still rather good.
As mentioned earlier, one has to have a large set of data for this too work well. Interesting this may be, but what kind of practical use is it? It can be applied to accountancy - if one has a large enough set of data in the accounts and the leading digits of the data do not fit Benford's Law then maybe one should suspect that somebody has been fiddling the books. Humans are rather poor at making up lots of "random" values that don't skew Benford's Law.
One more interesting fact is that it applies even if one rescales the data. For example, if you are looking at accounts in terms of £ sterling and covert it into US dollars or Albanian Lek the rescaled data still obeys Benford's Law. Thus if re-ran my tests and didn't analyse the size of files in bytes but instead used size in 512 byte blocks it still would produce a leading digit distribution that obeyed Benford's Law. Nice.
How can we apply this in computing? Perhaps we could use it to detect tampering with the sizes of a large set of files. Who knows? I am sure somebody can think of a useful way to use it. I just find it all rather fascinating.
Friday, 16 November 2012
Non linear characteristics in a draining battery on the Nexus 7
Measuring power consumption on low power devices really is not as simple as running tools such as PowerTop and then assuming the data is trustworthy. I shall explain why.
With Ubuntu on the Nexus 7, the battery driver originally provided battery capacity in terms of percentage full, which lacked precision to make any sane power consumption estimates. We tweaked the battery driver so that we could get battery capacity in terms of uWh from the bq27541 battery fuel gauge. From this, one can measure the change in capacity over time and estimate the power consumed by the device.
For the Ubuntu 12.04 Precise release I wrote the lightweight power measurement tool "powerstat" to try to determine power consumption using the change in battery capacity. Powerstat can gather changes in the battery capacity level and by using a simple sliding window on the samples it gives an estimate on the power being consumed over time. With laptops that consume a lot of power this provides a reasonable rough estimate of power consumption.
The tweak to the Nexus 7 battery driver allows powerstat to work on the Nexus 7 running Ubuntu. So how trustworthy is the battery data from the battery fuel gauge? Is the data reliable if we repeat the test under the same conditions? Do we get consistent readings over time?
For my first set of tests, I fully charged the Nexus 7 and then fully loaded the 4 CPUs with busy loops and then ran multiple powerstat tests; powerstat gathers samples over 8 minutes and estimates power consumption. It also calculates the standard deviation from these samples to give us some idea of the variability of the battery power measurements. For each powerstat test I logged the battery voltage level, the % battery capacity (normalized to a range of 0..1 to make it easier to plot), the estimated power consumption (with its standard deviation) and then plotted the results:
 With this test the machine is in a steady state, we are not changing the load on the CPUs, so one should expect a steady power measurement. But as one can see, the battery gauge informs us that the voltage is dropping over time (from ~4V down to ~3.25V) and the estimated power also varies from 4.6W down to 3.3W. So, clearly, the power estimate will depend on the level of charge in the battery.
With this test the machine is in a steady state, we are not changing the load on the CPUs, so one should expect a steady power measurement. But as one can see, the battery gauge informs us that the voltage is dropping over time (from ~4V down to ~3.25V) and the estimated power also varies from 4.6W down to 3.3W. So, clearly, the power estimate will depend on the level of charge in the battery.
I also measured an idle machine:
 Again, voltage drops over time and estimated power drops too. More interesting is that the estimated power measurement is not particularly smooth over time as shown by the plot of the standard deviation too. We can therefore conclude that a lightly loaded machine has a lot of variability in the estimated power consumption data and this means we cannot realistically measure subtle power optimization tweaks made to the software as there is just too much variability in the data.
Again, voltage drops over time and estimated power drops too. More interesting is that the estimated power measurement is not particularly smooth over time as shown by the plot of the standard deviation too. We can therefore conclude that a lightly loaded machine has a lot of variability in the estimated power consumption data and this means we cannot realistically measure subtle power optimization tweaks made to the software as there is just too much variability in the data.
I re-ran the idle test over several days, running from the same fully charged state to a completely empty battery, and compared runs. I got variability in the duration of the test (+/- 5%). Also, comparing estimated power consumption at the 100%, 75%, 50% and 25% battery capacity points also shows a lot of variability. This means one cannot get accurate and repeatable power estimations even when the battery is charged at specific capacities.
So next time somebody tells you that the latest changes made their low power device suck more (or less!) power than the previous release and their findings are based on data derived from battery fuel gauge, take it with a pinch of salt.
The only reliable way to measure instantaneous power consumption is using specialised precision equipment that has been accurately calibrated.
With Ubuntu on the Nexus 7, the battery driver originally provided battery capacity in terms of percentage full, which lacked precision to make any sane power consumption estimates. We tweaked the battery driver so that we could get battery capacity in terms of uWh from the bq27541 battery fuel gauge. From this, one can measure the change in capacity over time and estimate the power consumed by the device.
For the Ubuntu 12.04 Precise release I wrote the lightweight power measurement tool "powerstat" to try to determine power consumption using the change in battery capacity. Powerstat can gather changes in the battery capacity level and by using a simple sliding window on the samples it gives an estimate on the power being consumed over time. With laptops that consume a lot of power this provides a reasonable rough estimate of power consumption.
The tweak to the Nexus 7 battery driver allows powerstat to work on the Nexus 7 running Ubuntu. So how trustworthy is the battery data from the battery fuel gauge? Is the data reliable if we repeat the test under the same conditions? Do we get consistent readings over time?
For my first set of tests, I fully charged the Nexus 7 and then fully loaded the 4 CPUs with busy loops and then ran multiple powerstat tests; powerstat gathers samples over 8 minutes and estimates power consumption. It also calculates the standard deviation from these samples to give us some idea of the variability of the battery power measurements. For each powerstat test I logged the battery voltage level, the % battery capacity (normalized to a range of 0..1 to make it easier to plot), the estimated power consumption (with its standard deviation) and then plotted the results:
I also measured an idle machine:
I re-ran the idle test over several days, running from the same fully charged state to a completely empty battery, and compared runs. I got variability in the duration of the test (+/- 5%). Also, comparing estimated power consumption at the 100%, 75%, 50% and 25% battery capacity points also shows a lot of variability. This means one cannot get accurate and repeatable power estimations even when the battery is charged at specific capacities.
So next time somebody tells you that the latest changes made their low power device suck more (or less!) power than the previous release and their findings are based on data derived from battery fuel gauge, take it with a pinch of salt.
The only reliable way to measure instantaneous power consumption is using specialised precision equipment that has been accurately calibrated.
Saturday, 3 November 2012
Counting code size with SLOCCount
David A. Wheeler's SLOCCount is a useful tool for counting lines of code in a software project. It is simple to use, just provide it with the path to the source code and let it grind through all the source files. The resulting output is a break down of code line count for each type of source based on the programming language.
SLOCCount also estimates development time in person-years as well as the number of developers and the cost to develop. One can override the defaults and specify parameters such as costs per person, overhead and effort to make it match to your development model.
Of course, like all tools that produce metrics it can be abused, for example using it as a meaningless metric of programmer productivity. Counting lines of code does not really measure project complexity, a vexing bug that took 2 days to figure out and resulted in a 1 line fix is obviously more expensive than a poorly written 500 line function that introduces a no new noticeable functionality. As a rule of thumb, SLOCCount is a useful tool to get an idea of the size of a project and some idea of the cost to develop it. There are of course more complex ways to examine project source code, such as cyclomatic complexity metrics, and there are specific tools such as Panopticode that do this.
As a small exercise, I gave SLOCCount the task of counting the lines of code in the Linux kernel from version 2.6.12 to 3.6 and used the default settings to produce an estimated cost to develop each version.

It is interesting to see that the rate of code being added seemed to increase around the 2.6.28 release. So what about the estimated cost to develop?..

This is of course pure conjecture. The total lines of code does not consider the code of some patches that remove code and assumes that the cost is directly related to lines of code. Also, code complexity makes some lines of code far more expensive to develop than others. It is interesting to see that each release is adding an average of 184,000 lines of code per release which SLOCCount estimates to cost about $8.14 million dollars or ~44.24 dollars per line of code; not sure how realistic that really is.
Anyhow, SLOCCount is easy to use and provides some very useful rule-of-thumb analysis on project size and costs.
SLOCCount also estimates development time in person-years as well as the number of developers and the cost to develop. One can override the defaults and specify parameters such as costs per person, overhead and effort to make it match to your development model.
Of course, like all tools that produce metrics it can be abused, for example using it as a meaningless metric of programmer productivity. Counting lines of code does not really measure project complexity, a vexing bug that took 2 days to figure out and resulted in a 1 line fix is obviously more expensive than a poorly written 500 line function that introduces a no new noticeable functionality. As a rule of thumb, SLOCCount is a useful tool to get an idea of the size of a project and some idea of the cost to develop it. There are of course more complex ways to examine project source code, such as cyclomatic complexity metrics, and there are specific tools such as Panopticode that do this.
As a small exercise, I gave SLOCCount the task of counting the lines of code in the Linux kernel from version 2.6.12 to 3.6 and used the default settings to produce an estimated cost to develop each version.
It is interesting to see that the rate of code being added seemed to increase around the 2.6.28 release. So what about the estimated cost to develop?..
This is of course pure conjecture. The total lines of code does not consider the code of some patches that remove code and assumes that the cost is directly related to lines of code. Also, code complexity makes some lines of code far more expensive to develop than others. It is interesting to see that each release is adding an average of 184,000 lines of code per release which SLOCCount estimates to cost about $8.14 million dollars or ~44.24 dollars per line of code; not sure how realistic that really is.
Anyhow, SLOCCount is easy to use and provides some very useful rule-of-thumb analysis on project size and costs.
Saturday, 13 October 2012
Intel rdrand instruction revisited
A few months ago I did a quick and dirty benchmark of the Intel rdrand instruction found on the new Ivybridge processors. I did some further analysis a while ago and I've only just got around to writing up my findings. I've improved the test by exercising the Intel Digital Random Number Generator (DRNG) with multiple threads and also re-writing the rdrand wrapper in assembler and ensuring the code is inline'd. The source code for this test is available here.
So, how does it shape up? On a i5-3210M (2.5GHz) Ivybridge (2 cores, 4 threads) I get a peak of ~99.6 million 64 bit rdrands per second with 4 threads which equates to ~6.374 billion bits per second. Not bad at all.
 With a 4 threaded i5-3210M CPU we hit maximum rdrand throughput with 4 threads.
With a 4 threaded i5-3210M CPU we hit maximum rdrand throughput with 4 threads.
 ..and with a 8 threaded i7-3770 (3.4GHz) Ivybridge (4 cores, 8 threads) we again hit a peak throughput of 99.6 million 64 bit rdrands a second on 3 threads. One can therefore conclude that this is the peak rate of the DNRG on both CPUs tested. A 2 threaded i3 Ivybridge CPU won't be able to hit the peak rate of the DNRG, and a 4 threaded i5 can only just max out the DNRG with some hand-optimized code.
..and with a 8 threaded i7-3770 (3.4GHz) Ivybridge (4 cores, 8 threads) we again hit a peak throughput of 99.6 million 64 bit rdrands a second on 3 threads. One can therefore conclude that this is the peak rate of the DNRG on both CPUs tested. A 2 threaded i3 Ivybridge CPU won't be able to hit the peak rate of the DNRG, and a 4 threaded i5 can only just max out the DNRG with some hand-optimized code.
Now how random is this random data? There are several tests available; I chose to exercise the DRNG using the dieharder test suite. The test is relatively simple; install dieharder and do 64 bit rdrand reads and output these as a raw random number stream and pipe this into dieharder:
..and leave to cook for about 45 minutes. The -g 200 option specifies that the random numbers come from stdin and the -a option runs all the dieharder tests. All the tests passed with the exception of the diehard_sums test which produced "weak" results, however, this test is known to be unreliable and recommended not to be used. Quite honestly, I would be surprised if the tests failed, but you never know until one runs them.
The CA cert research labs have an on-line random number generator analysis website allowing one to submit and test at least 12 MB of random numbers. I submitted 32 MB of data, and I am currently waiting to see if I get any results back. Watch this space.
So, how does it shape up? On a i5-3210M (2.5GHz) Ivybridge (2 cores, 4 threads) I get a peak of ~99.6 million 64 bit rdrands per second with 4 threads which equates to ~6.374 billion bits per second. Not bad at all.
Now how random is this random data? There are several tests available; I chose to exercise the DRNG using the dieharder test suite. The test is relatively simple; install dieharder and do 64 bit rdrand reads and output these as a raw random number stream and pipe this into dieharder:
sudo apt-get install dieharder
./rdrand-test | dieharder -g 200 -a
#=============================================================================#
# dieharder version 3.31.1 Copyright 2003 Robert G. Brown #
#=============================================================================#
rng_name |rands/second| Seed |
stdin_input_raw| 3.66e+07 | 639263374|
#=============================================================================#
test_name |ntup| tsamples |psamples| p-value |Assessment
#=============================================================================#
diehard_birthdays| 0| 100| 100|0.40629140| PASSED
diehard_operm5| 0| 1000000| 100|0.79942347| PASSED
diehard_rank_32x32| 0| 40000| 100|0.35142889| PASSED
diehard_rank_6x8| 0| 100000| 100|0.75739694| PASSED
diehard_bitstream| 0| 2097152| 100|0.65986567| PASSED
diehard_opso| 0| 2097152| 100|0.24791918| PASSED
diehard_oqso| 0| 2097152| 100|0.36850828| PASSED
diehard_dna| 0| 2097152| 100|0.52727856| PASSED
diehard_count_1s_str| 0| 256000| 100|0.08299753| PASSED
diehard_count_1s_byt| 0| 256000| 100|0.31139908| PASSED
diehard_parking_lot| 0| 12000| 100|0.47786440| PASSED
diehard_2dsphere| 2| 8000| 100|0.93639860| PASSED
diehard_3dsphere| 3| 4000| 100|0.43241488| PASSED
diehard_squeeze| 0| 100000| 100|0.99088862| PASSED
diehard_sums| 0| 100| 100|0.00422846| WEAK
diehard_runs| 0| 100000| 100|0.48432365| PASSED
..
dab_monobit2| 12| 65000000| 1|0.98439048| PASSED
..and leave to cook for about 45 minutes. The -g 200 option specifies that the random numbers come from stdin and the -a option runs all the dieharder tests. All the tests passed with the exception of the diehard_sums test which produced "weak" results, however, this test is known to be unreliable and recommended not to be used. Quite honestly, I would be surprised if the tests failed, but you never know until one runs them.
The CA cert research labs have an on-line random number generator analysis website allowing one to submit and test at least 12 MB of random numbers. I submitted 32 MB of data, and I am currently waiting to see if I get any results back. Watch this space.
Sunday, 16 September 2012
Striving for better code quality.
Software is complex and is never bug free, but fortunately there are many different tools and techniques available to help to identify and catch a large class of common and obscure bugs.
Compilers provide build options that can help drive up code quality by being particularly strict to detect questionable code constructions, for example gcc's -Wall and -pedantic flags. The gcc -Werror flag is useful during code development to ensure compilation halts with an error on warning messages, this ensures the developer will stop and fix code.
Static analysis during compilation is also a very useful technique, tools such as smatch and Concinelle can identify bugs such as deferencing of NULL pointers, checks for return values and ranges, incorrect use of && and ||, bad use of unsigned or signed values and many more beside. These tools were aimed for use on the Linux kernel source code, but can be used on C application source too. Let's take a moment to see how to use smatch when building an application.
Download the dependencies:
Download and build smatch:
Now build your application using smatch:
..and inspect the warnings and errors in the file warnings.log. Smatch will produce false-positives, so not every warning or error is necessarily buggy code.
Of course, run time profiling of programs also can catch errors. Valgrind is an excellent run time profiler that I regularly use when developing applications to catch bugs such as memory leaks and incorrect memory read/writes. I recommend starting off using the following valgrind options:
For example:
Since the application is being run on a synthetic software CPU execution can be slow, however it is amazingly thorough and produces detailed output that is extremely helpful in cornering buggy code.
The gcc compiler also provides mechanism to instrument code for run-time analysis. The -fmudflap family of options instruments risky pointer and array dereferencing operations, some standard library string and heap functions as well as some other range + validity tests. For threaded applications use -fmudflapth instead of -fmudflap. The application also needs to be linked with libmudflap.
Here is a simple example:
Compile with:
..and mudflap detects the error:
These are just a few examples, however there are many other options too. Electric Fence is a useful malloc debugger, and gcc's -fstack-protector produces extra code to check for buffer overflows, for example in stack smashing. Tools like bfbtester allow us to brute force check command line overflows - this is useful as I don't know many developers who try to thoroughly validate all the options in their command line utilities.
No doubt there are many more tools and techniques available. If we use these wisely and regularly we can reduce bugs and drive up code quality.
Compilers provide build options that can help drive up code quality by being particularly strict to detect questionable code constructions, for example gcc's -Wall and -pedantic flags. The gcc -Werror flag is useful during code development to ensure compilation halts with an error on warning messages, this ensures the developer will stop and fix code.
Static analysis during compilation is also a very useful technique, tools such as smatch and Concinelle can identify bugs such as deferencing of NULL pointers, checks for return values and ranges, incorrect use of && and ||, bad use of unsigned or signed values and many more beside. These tools were aimed for use on the Linux kernel source code, but can be used on C application source too. Let's take a moment to see how to use smatch when building an application.
Download the dependencies:
sudo apt-get install libxml2-dev llvm-dev libsqlite3-dev
Download and build smatch:
mkdir ~/src
cd ~/src
git clone git://repo.or.cz/smatch
cd smatch
make
Now build your application using smatch:
cd ~/your_source_code
make clean
make CHECK="~/src/smatch/smatch --full-path" \
CC=~/src/smatch/cgcc | tee warnings.log
..and inspect the warnings and errors in the file warnings.log. Smatch will produce false-positives, so not every warning or error is necessarily buggy code.
Of course, run time profiling of programs also can catch errors. Valgrind is an excellent run time profiler that I regularly use when developing applications to catch bugs such as memory leaks and incorrect memory read/writes. I recommend starting off using the following valgrind options:
--leak-check=full --show-possibly-lost=yes --show-reachable=yes --malloc-fill=
For example:
valgrind --leak-check=full --show-possibly-lost=yes --show-reachable=yes \
--malloc-fill=ff your-program
Since the application is being run on a synthetic software CPU execution can be slow, however it is amazingly thorough and produces detailed output that is extremely helpful in cornering buggy code.
The gcc compiler also provides mechanism to instrument code for run-time analysis. The -fmudflap family of options instruments risky pointer and array dereferencing operations, some standard library string and heap functions as well as some other range + validity tests. For threaded applications use -fmudflapth instead of -fmudflap. The application also needs to be linked with libmudflap.
Here is a simple example:
int main(int argc, char **argv)
{
static int x[100];
return x[100];
}
Compile with:
gcc example.c -o example -fmudflap -lmudflap
..and mudflap detects the error:
./example
*******
mudflap violation 1 (check/read): time=1347817180.586313 ptr=0x701080 size=404
pc=0x7f98d3d17f01 location=`example.c:5:2 (main)'
/usr/lib/x86_64-linux-gnu/libmudflap.so.0(__mf_check+0x41) [0x7f98d3d17f01]
./example(main+0x7a) [0x4009c6]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xed) [0x7f98d397276d]
Nearby object 1: checked region begins 0B into and ends 4B after
mudflap object 0x190a370: name=`example.c:3:13 x'
bounds=[0x701080,0x70120f] size=400 area=static check=3r/0w liveness=3
alloc time=1347817180.586261 pc=0x7f98d3d175f1
number of nearby objects: 1
These are just a few examples, however there are many other options too. Electric Fence is a useful malloc debugger, and gcc's -fstack-protector produces extra code to check for buffer overflows, for example in stack smashing. Tools like bfbtester allow us to brute force check command line overflows - this is useful as I don't know many developers who try to thoroughly validate all the options in their command line utilities.
No doubt there are many more tools and techniques available. If we use these wisely and regularly we can reduce bugs and drive up code quality.
Wednesday, 22 August 2012
Virgin Media Super Hub and ssh timeouts
After upgrading to a new "shiny" Virgin Media Super Hub I started to get annoying ssh timeouts on idle connections. After some Googling around I discovered that it suffers from TCP connection timeouts and some users have suggested that there isn't much memory in the device, so it can't save much session data.
Well, how does one workaround this issue? Setting the keep alive probe down to 50 seconds and then resending it every 10 seconds seems to do the trick for me. I also tweaked the TCP settings so that if no ACK response is received for 5 consecutive times, the connection is marked as broken. Here's the quick one-liner fix:
Of course, to make these settings persistent across reboots, add them to /etc/sysctl.conf
I'm not sure if these settings are "optimal", but they do the trick. You're mileage may vary.
Well, how does one workaround this issue? Setting the keep alive probe down to 50 seconds and then resending it every 10 seconds seems to do the trick for me. I also tweaked the TCP settings so that if no ACK response is received for 5 consecutive times, the connection is marked as broken. Here's the quick one-liner fix:
sudo sysctl -w net.ipv4.tcp_keepalive_time=50 \
net.ipv4.tcp_keepalive_intvl=10 \
net.ipv4.tcp_keepalive_probes=5 Of course, to make these settings persistent across reboots, add them to /etc/sysctl.conf
I'm not sure if these settings are "optimal", but they do the trick. You're mileage may vary.
Tuesday, 21 August 2012
Testing eCryptfs
Over the past several months I've been occasionally back-porting a bunch of eCryptfs patches onto older Ubuntu releases. Each back-ported fix needs to be properly sanity checked and so I've been writing test cases for each one and adding them to the eCryptfs test suite.
To get hold of the test suite, check it out using bzr:
The -b option specifies the size in 1K blocks of the loop-back mounted /lower file system size. I generally use 1000000 blocks as a minimum.
The -D option specifies the path where the temporary loop-back mounted image is kept and the -l and -u options specified the paths of the lower and upper mount points.
By default the tests will use an ext4 lower filesystem. One can also run specify which file systems to run the tests on using the -f option, this can be a comma separated list of one or more file systems, for example:
We also run these tests regularly on new kernel images to ensure we don't introduce and regressions. As it stands, I'm currently adding in tests for each bug fix that we back-port and for most new bugs that require a thorough test. I hope to expand the breadth of the tests to ensure we get better general test coverage.
And finally, thanks to Tyler Hicks for writing the test framework and for his valuable help in describing how to construct a bunch of these tests.
To get hold of the test suite, check it out using bzr:
bzr checkout lp:ecryptfs
sudo apt-get install debhelper autotools-dev autoconf automake \
intltool libtool libgcrypt11-dev libglib2.0-dev libkeyutils-dev \
libnss3-dev libpam0g-dev pkg-config python-dev swig acl \
ecryptfs-utils libattr1-dev
sudo apt-get install xfsprogs btrfs-tools
cd ecryptfs
autoreconf -ivf
intltoolize -c -f
./configure --enable-tests --disable-pywrap
make
sudo mkdir /lower /upper
mkdir /tmp/image
sudo ./tests/run_tests.sh -K -c safe -b 1000000 -D /tmp/image -l /lower -u /upper
The -b option specifies the size in 1K blocks of the loop-back mounted /lower file system size. I generally use 1000000 blocks as a minimum.
The -D option specifies the path where the temporary loop-back mounted image is kept and the -l and -u options specified the paths of the lower and upper mount points.
By default the tests will use an ext4 lower filesystem. One can also run specify which file systems to run the tests on using the -f option, this can be a comma separated list of one or more file systems, for example:
sudo ./tests/run_tests.sh -K -c safe -b 1000000 -D /tmp/image -l /lower -u /upper \
-f ext2,ext3,ext4,xfs
sudo ./tests/run_tests.sh -K -c safe -b 1000000 -D /tmp/image -l /lower -u /upper \
-f ext2,ext3,ext4,xfs -t lp-926292.sh
We also run these tests regularly on new kernel images to ensure we don't introduce and regressions. As it stands, I'm currently adding in tests for each bug fix that we back-port and for most new bugs that require a thorough test. I hope to expand the breadth of the tests to ensure we get better general test coverage.
And finally, thanks to Tyler Hicks for writing the test framework and for his valuable help in describing how to construct a bunch of these tests.
Tuesday, 7 August 2012
Simple performance test of rdrand
My new Lenovo X230 laptop is equipped with a Intel(R) i5-3210M CPU (2.5 GHz, with 3.1 GHz Turbo) which supports the new Digital Random Number Generator (DRNG) - a high performance entropy and random number generator. The DNRG is read using the new Intel rdrand instruction which can return 64, 32 or 16 bit random numbers.
The DRNG is described in detail in this article and provides very useful code examples in assembler and C which I used to write a simple and naive test to see how well the rdrand performs on my i5-3210M.
For my test, I simply read 100 million 64 bit random numbers on a single thread. The Intel literature states one can get up to about 70 million rdrand invocations per second on 8 threads, so my simple test is rather naive as it only exercises rdrand on one thread. For a set of 10 iterations on my test, I'm getting around 40-45 nanoseconds per rdrand, or about 22-25 million rdrands per second, which is really impressive. The test is a mix of assembler and C, and is not totally optimal, so I am sure I can squeeze a little more performance out with some extra work.
The next test I suspect is to see just random the data is and to see how well it compares to other software random number generators... but I will tinker with that after my vacation.
Anyhow, for reference, the test can be found here in my git repository.
The DRNG is described in detail in this article and provides very useful code examples in assembler and C which I used to write a simple and naive test to see how well the rdrand performs on my i5-3210M.
For my test, I simply read 100 million 64 bit random numbers on a single thread. The Intel literature states one can get up to about 70 million rdrand invocations per second on 8 threads, so my simple test is rather naive as it only exercises rdrand on one thread. For a set of 10 iterations on my test, I'm getting around 40-45 nanoseconds per rdrand, or about 22-25 million rdrands per second, which is really impressive. The test is a mix of assembler and C, and is not totally optimal, so I am sure I can squeeze a little more performance out with some extra work.
The next test I suspect is to see just random the data is and to see how well it compares to other software random number generators... but I will tinker with that after my vacation.
Anyhow, for reference, the test can be found here in my git repository.
Tuesday, 24 July 2012
Using virt-manager to manage KVM and QEMU instances
I've been using QEMU and KVM for quite a while now for general kernel testing, for example, sanity checking eCryptfs and Ceph. It can be argued that the best kind of testing is performed on real hardware, however, there are times when it is much more convenient (and faster) to exercise kernel fixes on a virtual machine.
I used to use the command line incantations to run QEMU and KVM, but recently I've moved over to using virt-manager because it so much simpler to use and caters for most of my configuration needs.
Virt-manager provides a very usable GUI and allows one to create, manage, clone and destroy virtual machine instances with ease.
I used to use the command line incantations to run QEMU and KVM, but recently I've moved over to using virt-manager because it so much simpler to use and caters for most of my configuration needs.
Virt-manager provides a very usable GUI and allows one to create, manage, clone and destroy virtual machine instances with ease.
 |
| virt-manager view of virtual machines |
Each virtual machine can be easy reconfigured in terms of CPU configuration (number and type of CPUs), memory size, boot options, disk and CD-ROM selection, NIC selection, display server (VNC or Spice), sound device, serial port config, video hardware and USB and IDE controller config.
One can add and remove additional hardware, such serial port, parallel ports, USB and PCI host devices, watchdog controllers and much more besides.
 |
| Configuring a virtual machine |
..so reconfiguring a test to run on a single core CPU to multi-core is a simple case of shutting down the virtual machine, bumping up the number of CPUs and booting up again.
By default one can view the virtual machine's console via a VNC viewer in virt-manager and there is provision to scale the screen to the window size, set to full size or resize the virt-manager window to the screen size. For ease of use, I generally just ssh into the virtual machines and ignore the console unless I can't get the kernel to boot.
 |
| virt-manager viewing a 64 bit Natty server (for eCryptfs testing) |
Virt-manager is a great tool and well worth giving a spin. For more information on virt-manager visit virt-manager.org
Tuesday, 19 June 2012
Ubuntu ODM portal
A new Ubuntu portal http://odm.ubuntu.com is a jump-start page containing links to pages and documents useful for Original Design Manufactures (ODMs), Original Equipment Manufacturers (OEMs) and Independent BIOS vendors.
Some of the highlights include:
Kudos to Chris Van Hoof for organizing this useful portal.
Some of the highlights include:
- A BIOS/UEFI requirements document that containing recommendations to ensure firmware is compatible with the Linux kernel.
- Getting started links describing how to download, install, configure and debug Ubuntu.
- Links to certified hardware, debugging tools, SystemTap guides, packaging guides, kernel building notes.
- Debugging tips, covering: hotkeys, suspend/resume, sound, X and wireless and an A5 sized Ubuntu Debugging booklet.
- Link to fwts-live, the Firmware Test Suite live image.
Kudos to Chris Van Hoof for organizing this useful portal.
Friday, 1 June 2012
Intel ® SSD 520 Goodness
 I've been fortunate to get my hands on an Intel ® 520 2.5" 240GB Solid State Drive so I thought I'd put it through some relatively simple tests to see how well it performs.
I've been fortunate to get my hands on an Intel ® 520 2.5" 240GB Solid State Drive so I thought I'd put it through some relatively simple tests to see how well it performs.Power Consumption
My first round of tests involved seeing how well it performs in terms of power consumption compared to a typical laptop spinny Hard Disk Drive. I rigged up a Lenovo X220i (i3-2350M @ 2.30GHz) running Ubuntu Precise 12.04 LTS (x86-64) to a Fluke 8846A precision digital multimeter and then compared the SSD with a 320GB Seagate ST320LT020-9YG142 HDD against some simple I/O tests. Each test scenario was run 5 times and I based my results of the average of these 5 runs.
The Intel ® 520 2.5" SSD fits into conventional drive bays but comes with a black plastic shim attached to one side that has to be first removed to reduce the height so that it can be inserted into the Lenovo X220i low profile drive bay. This is a trivial exercise and takes just a few moments with a suitable Phillips screwdriver. (As a bonus, the SSD also comes with a 3.5" adapter bracket and SATA 6.0 signal and power cables allowing it to be easily added into a Desktop too).
In an idle state, the HDD pulled ~25mA more than the SSD, so in overall power consumption terms the SSD saves ~5%, (e.g. adds ~24 minutes life to an 8 hour battery).
I then exercised the ext4 file system with Bonnie++ and measured the average current drawn during the run and using the idle "baseline" calculated the power consumed for the duration of the test. The SSD draws more current than the HDD, however it ran the Bonnie++ test ~4.5 times faster and so the total power consumed to get the same task completed was less, typically 1/3 of the power of the HDD.
Using dd, I next wrote 16GB to the devices and found the SSD was ~5.3 times faster than the HDD and consumed ~ 1/3 the power of the HDD. For a 16GB read, the SSD was ~5.6 times faster than the HDD and used about 1/4 the power of the HDD.
Finally, using tiobench I calculated that the SSD was ~7.6 times faster than the HDD and again used about 1/4 the power of the HDD.
So, overall, very good power savings. The caveat is that since the SSD consumes more power than the HDD per second (but gets way more I/O completed) one can use more power with the SSD if one is using continuous I/O all the time. You do more, and it costs more; but you get it done faster, so like for like the SSD wins in terms of reducing power consumption.
Boot Speed
Although ureadhead tries hard to optimize the inode and data reads during boot, the HDD is always going to perform badly because of seek latency and slow data transfer rates compared to any reasonable SSD. Using bootchart and five runs the average time to boot was ~7.9 seconds for the SSD and ~25.8 seconds for the HDD, so the SSD improved boot times by a factor of about 3.2 times. Read rates were topping ~420 MB/sec which was good, but could have been higher for some (yet unknown) reason.
Palimpsest Performance Test
Palimpsest (aka "Disk Utility") has a quick and easy to use drive benchmarking facility that I used to measure the SSD read/write rates and access times. Since writing to the drive destroys the file system I rigged the SSD up in a SATA3 capable desktop as a 2nd drive and then ran the tests. Results are very impressive:
 Average Read Rate: 535.8 MB/sec
Average Read Rate: 535.8 MB/secAverage Write Rate: 539.5 MB/sec
Average Access Time: sub 0.1 milliseconds.
This is ~7 x faster in read/write speed and ~200-300 x faster in access time compared to the Seagate HDD.
File System Benchmarks
So which file system performs best on the SSD? Well, it depends on the use case. There are may different file system benchmarking tools available and each one addresses different types of file system behaviour. Which ever test I use it most probably won't match your use case(!) Since SSDs have very small latency overhead it is worth exercising various file systems with multiple threaded I/O read/writes and see how well these perform. I rigged up the threaded I/O benchmarking tool tiobench to exercise ext2, ext3, ext4, xfs and btrfs while varying the number of threads from 1 to 128 in powers of 2. In theory the SSD can do multiple random seeks very efficiently, so this type of testing should show the point where the SSD has optimal performance with multiple I/O requests.
Sequential Read Rates
Sequential Write Rates
xfs is consistently best, where as btrfs performs badly with the low thread count.
Sequential Read Latencies

These scale linearly with the number of threads and all file systems follow the same trend.
Sequential Write Latencies

Again, linear scaling of latencies with number of threads.
Random Read Rates
Again, best transfer rates seem to occur at with 32-64 threads, and btrfs does not seem to perform that well compared to ext2, ext3, ext4 and xfs
Random Write Rates
Interestingly ext2 and ext3 fair well with ext4 and xfs performing very similarly and btrfs performing worst again.
Random Read Latencies

Again the linear scaling with latency as thread count increases with very similar performance between all file systems. In this case, btrfs performs best.
Random Write Latencies

Which I/O scheduler should I use?
Anecdotal evidence suggests using the noop scheduler should be best for an SSD. In this test I exercised ext4, xfs and btrfs with Bonnie++ using the CFQ, Noop and Deadline schedulers. The tests were run 5 times and below are the averages of the 5 test runs.
ext4:
| CFQ | Noop | Deadline | |
| Sequential Block Write (K/sec): | 506046 | 513349 | 509893 |
| Sequential Block Re-Write (K/sec): | 213714 | 231265 | 217430 |
| Sequentual Block Read (K/sec): | 523525 | 551009 | 508774 |
So for ext4 on this SSD, Noop is a clear winner for sequential I/O.
xfs:
| CFQ | Noop | Deadline | |
| Sequential Block Write (K/sec): | 514219 | 514367 | 514815 |
| Sequential Block Re-Write (K/sec): | 229455 | 230845 | 252210 |
| Sequentual Block Read (K/sec): | 526971 | 550393 | 553543 |
It appears that Deadline for xfs seems to perform best for sequential I/O.
btrfs:
| CFQ | Noop | Deadline | |
| Sequential Block Write (K/sec): | 511799 | 431700 | 430780 |
| Sequential Block Re-Write (K/sec): | 252210 | 253656 | 242291 |
| Sequentual Block Read (K/sec): | 629640 | 655361 | 659538 |
And for btrfs, Noop is marginally better for sequential writes and re-writes but Deadline is best for reads.
So it appears for sequential I/O operations, CFQ is the least optimal choice with Noop being a good choice for ext4, deadline for xfs and either for btrfs. However, this is just based on Sequential I/O testing and we should explore Random I/O testing before drawing any firm conclusions.
Conclusion
As can be seen from the data, SSD provide excellent transfer rates, incredibly short latencies as well as a reducing power consumption. At the time of writing the cost per GB for an SSD is typically slightly more than £1 per GB which is around 5-7 times more expensive than a HDD. Since I travel quite frequently and have damaged a couple of HDDs in the last few years the shock resistance, performance and power savings of the SSD are worth paying for.
Saturday, 3 March 2012
Dell 1525 battery not charging
My wife's Dell 1525 Ubuntu laptop starting having battery problems last year and eventually we ended up with a totally dead Li-ion battery. Fortunately I was able to acquire a clone replacement for about £25 which charged fine and worked for a week before becoming totally drained.
According to some users, this happens because the charging circuitry has died, which was a little alarming since the machine was way out of warranty. So I had a machine that runs fine on AC power, but the battery won't charge. So I slept on the problem and this morning I thought I'd try another spare Dell AC adapter just to factor out the AC power supply. To my surprise the battery started charging, so I had to conclude the problem is simply due to a broken AC power supply.
So if the AC power supply is not charging, perhaps the original battery wasn't dead after all. I plugged in the old battery, gave it an hour to charge but found it really was dead and useless.
I've compared the characteristics of the working power supply against the broken one with a multimeter and I cannot see any difference, which strikes me a little curious. If anyone has any ideas why one works and other other doesn't please let me know!
UPDATE
After a bit of research I found a relevant article at laptop-junction.com [1] that describes the AC adapter battery charging issue. So it seems that this is a common issue [2] for a bunch of AC adapters and the author suggests a possible design issue [3].
References:
[1] http://www.laptop-junction.com/toast/content/battery-not-charging
[2] http://www.laptop-junction.com/toast/content/dell-ac-power-adapter-not-recognized
[3] http://www.laptop-junction.com/toast/content/dell-ac-power-adapter-id-chip-died
According to some users, this happens because the charging circuitry has died, which was a little alarming since the machine was way out of warranty. So I had a machine that runs fine on AC power, but the battery won't charge. So I slept on the problem and this morning I thought I'd try another spare Dell AC adapter just to factor out the AC power supply. To my surprise the battery started charging, so I had to conclude the problem is simply due to a broken AC power supply.
So if the AC power supply is not charging, perhaps the original battery wasn't dead after all. I plugged in the old battery, gave it an hour to charge but found it really was dead and useless.
I've compared the characteristics of the working power supply against the broken one with a multimeter and I cannot see any difference, which strikes me a little curious. If anyone has any ideas why one works and other other doesn't please let me know!
UPDATE
After a bit of research I found a relevant article at laptop-junction.com [1] that describes the AC adapter battery charging issue. So it seems that this is a common issue [2] for a bunch of AC adapters and the author suggests a possible design issue [3].
References:
[1] http://www.laptop-junction.com/toast/content/battery-not-charging
[2] http://www.laptop-junction.com/toast/content/dell-ac-power-adapter-not-recognized
[3] http://www.laptop-junction.com/toast/content/dell-ac-power-adapter-id-chip-died
Saturday, 25 February 2012
RC6 Call for testing in Ubuntu 12.04 Precise Pangolin LTS, part 2
The Ubuntu Kernel Team has uploaded a new kernel (3.2.0-17.27) which contains an additional fix to resolve the remaining issues seen with the RC6 power saving enabled. For users with Sandy Bridge based hardware we would appreciate them to run the tests described on https://wiki.ubuntu.com/Kernel/PowerManagementRC6 and add their results to that page.
Sunday, 19 February 2012
RC6 Call for testing in Ubuntu 12.04 Precise Pangolin LTS
The Ubuntu Kernel Team has released a call for testing for a set of RC6 power saving patches for Ubuntu 12.04 Precise Pangolin LTS. Quoting Leann Ogasawara's email to the ubuntu kernel team and ubuntu-devel mailing lists:
"Hi All,
RC6 is a technology which allows the GPU to go into a very low power consumption state when the GPU is idle (down to 0V). It results in considerable power savings when this stage is activated. When comparing under idle loads with machine state where RC6 is disabled, improved power usage of around 40-60% has been witnessed [1].
Up until recently, RC6 was disabled by default for Sandy Bridge systems due to reports of hangs and graphics corruption issues when RC6 was enabled. Intel has now asserted that RC6p (deep RC6) is responsible for the RC6 related issues on Sandy Bridge. As a result, a patch has recently been submitted upstream to disable RC6p for Sandy Bridge [2].
In an effort to provide more exposure and testing for this proposed patch, the Ubuntu Kernel Team has applied this patch to 3.2.0-17.26 and newer Ubuntu 12.04 Precise Pangolin kernels. We have additionally enabled plain RC6 by default on Sandy Bridge systems so that users can benefit from the improved power savings by default.
We have decided to post a widespread call for testing from Sandy Bridge owners running Ubuntu 12.04. We hope to capture data which supports the the claims of power saving improvements and therefore justify keeping these patches in the Ubuntu 12.04 kernel. We also want to ensure we do not trigger any issues due to plain RC6 being enabled by default for Sandy Bridge.
If you are running Ubuntu 12.04 (Precise Pangolin) and willing to test and provide feedback, please refer to our PowerManagementRC6 wiki for detailed instructions [3]. Additionally, instructions for reporting any issues with RC6 enabled are also noted on the wiki. We would really appreciate any testing and feedback users are able to provide.
Thanks in advance,
The Ubuntu Kernel Team"
So please contribute to this call for testing by visiting https://wiki.ubuntu.com/Kernel/PowerManagementRC6 and follow the instructions. Thank you!
"Hi All,
RC6 is a technology which allows the GPU to go into a very low power consumption state when the GPU is idle (down to 0V). It results in considerable power savings when this stage is activated. When comparing under idle loads with machine state where RC6 is disabled, improved power usage of around 40-60% has been witnessed [1].
Up until recently, RC6 was disabled by default for Sandy Bridge systems due to reports of hangs and graphics corruption issues when RC6 was enabled. Intel has now asserted that RC6p (deep RC6) is responsible for the RC6 related issues on Sandy Bridge. As a result, a patch has recently been submitted upstream to disable RC6p for Sandy Bridge [2].
In an effort to provide more exposure and testing for this proposed patch, the Ubuntu Kernel Team has applied this patch to 3.2.0-17.26 and newer Ubuntu 12.04 Precise Pangolin kernels. We have additionally enabled plain RC6 by default on Sandy Bridge systems so that users can benefit from the improved power savings by default.
We have decided to post a widespread call for testing from Sandy Bridge owners running Ubuntu 12.04. We hope to capture data which supports the the claims of power saving improvements and therefore justify keeping these patches in the Ubuntu 12.04 kernel. We also want to ensure we do not trigger any issues due to plain RC6 being enabled by default for Sandy Bridge.
If you are running Ubuntu 12.04 (Precise Pangolin) and willing to test and provide feedback, please refer to our PowerManagementRC6 wiki for detailed instructions [3]. Additionally, instructions for reporting any issues with RC6 enabled are also noted on the wiki. We would really appreciate any testing and feedback users are able to provide.
Thanks in advance,
The Ubuntu Kernel Team"
So please contribute to this call for testing by visiting https://wiki.ubuntu.com/Kernel/PowerManagementRC6 and follow the instructions. Thank you!
Friday, 17 February 2012
Introducing the Firmware Test Suite Live (fwts-live)
Firmware Test Suite Live (fwts-live) is a USB live image that will automatically boot and run the Firmware Test Suite (fwts) - it will run on legacy BIOS and also UEFI firmware (x86_64) bit systems.
fwts-live will run a range of fwts tests and store the results on the USB stick - these can be reviewed while running fwts-live or at a later time on another computer if required.
To install fwts-live on to a USB first download either a 32 or 64 bit image from http://odm.ubuntu.com/fwts-live/ and then uncompress the image using:
Next insert a USB stick into your machine and unmount it. Now one has to copy the fwts-live image to the USB stick - one can find the USB device using:
..so the above example it is /dev/sdb, and copy using:
..and then remove the USB stick.
To run, insert the USB stick into the machine you want to test and then boot the machine. This will start up fwts-live and then you will be shown a set of options - to either run all the fwts batch tests, to select individual tests to run, or abort testing and shutdown.

If you chose to run all the fwts batch tests then fwts will automatically run through a series of tests which will take a few minutes to complete:

and when complete one can chose to view the results log:

if "Yes" is selected then one can view the results. The cursor up/down and page up/down keys can be used to navigate the results log file. When you have completed viewing the results log, fwts-live will inform you where the results have been saved on the USB stick (so that one can review them later by plugging the USB stick into a different machine).

A full user guide to fwts-live is available at: https://wiki.ubuntu.com/HardwareEnablementTeam/Documentation/FirmwareTestSuiteLive
To help interpret any errors or warnings found by fwts we recommend visiting fwts reference guide - this is has comprehensive description of each test and detailed explanations of warnings and error messages.
Below is a demo of fwts-live running inside QEMU:
fwts-live will run a range of fwts tests and store the results on the USB stick - these can be reviewed while running fwts-live or at a later time on another computer if required.
To install fwts-live on to a USB first download either a 32 or 64 bit image from http://odm.ubuntu.com/fwts-live/ and then uncompress the image using:
bunzip2 fwts-live-*.img.bz2
Next insert a USB stick into your machine and unmount it. Now one has to copy the fwts-live image to the USB stick - one can find the USB device using:
dmesg | tail -10 | grep Attached
[ 2525.654620] sd 6:0:0:0: [sdb] Attached SCSI removable disk
..so the above example it is /dev/sdb, and copy using:
sudo dd if=fwts-live-oneiric-*.img of=/dev/sdb
sync
..and then remove the USB stick.
To run, insert the USB stick into the machine you want to test and then boot the machine. This will start up fwts-live and then you will be shown a set of options - to either run all the fwts batch tests, to select individual tests to run, or abort testing and shutdown.

If you chose to run all the fwts batch tests then fwts will automatically run through a series of tests which will take a few minutes to complete:
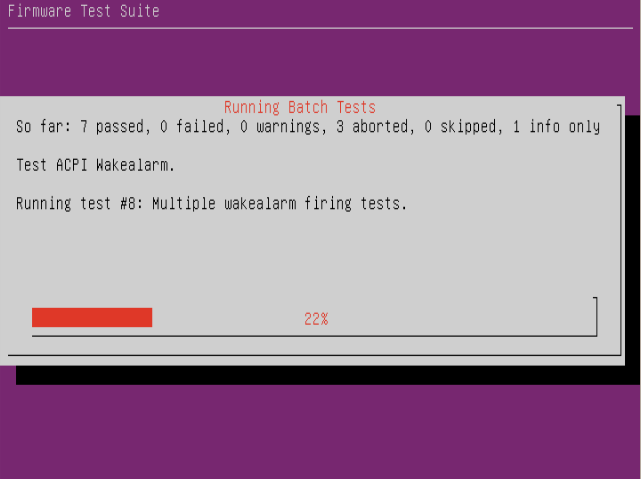
and when complete one can chose to view the results log:

if "Yes" is selected then one can view the results. The cursor up/down and page up/down keys can be used to navigate the results log file. When you have completed viewing the results log, fwts-live will inform you where the results have been saved on the USB stick (so that one can review them later by plugging the USB stick into a different machine).

A full user guide to fwts-live is available at: https://wiki.ubuntu.com/HardwareEnablementTeam/Documentation/FirmwareTestSuiteLive
To help interpret any errors or warnings found by fwts we recommend visiting fwts reference guide - this is has comprehensive description of each test and detailed explanations of warnings and error messages.
Below is a demo of fwts-live running inside QEMU:
Kudos to Chris Van Hoof for producing fwts-live
Wednesday, 1 February 2012
3G using a Huawei E1552/E1800 (HSPA modem) on Ubuntu
So my internet service provider is rolling out a programme of speed upgrades and over the past few weeks I've suffered from various connectivity issues most probably because of infrastructure upgrades. I lost connectivity today at 6am and was told to expect to be connected by 9pm, so I popped down town and acquired a 3G USB dongle and a suitable data plan/ contract for my needs.
Typically these USB dongles are designed to appear as USB media devices (e.g. pseudo CD-ROM) and one has to mode switch it to a USB modem. Unfortunately I had a Huawei E1552/E1800 which required some USB mode switching magic, but to find this I first required internet connectivity. Fortunately I had a sacrificial laptop which I installed an old version of Windows XP which allowed me to then connect to the internet using the 3G USB dongle and I was able to then track down the appropriate runes. OK, I feel bad about installing Windows XP, but I was being pragmatic - I needed connectivity!
The procedure to get this device working on Ubuntu wasn't too bad. First I identified the USB dongle using lsusb to get the vendor and product IDs (12d1:1446):
Bus 002 Device 013: ID 12d1:1446 Huawei Technologies Co., Ltd. E1552/E1800 (HSPA modem)
Then I added the following runes to /etc/usb_modeswitch.conf -
..this appears in many forums on the internet, kudos to whoever figured this out.
Then I ran "sudo usb_modeswitch -c /etc/usb_modeswitch.conf" and this switched the dongle into:
Bus 002 Device 012: ID 12d1:14ac Huawei Technologies Co., Ltd.
..and I was then able to simply connect using network manager. Result!
** UPDATE **
Mathieu Trudel-Lapierre fixed this (9th Feb 2012) and now Ubuntu Precise works perfectly with the Huawei E1552/E1800. Thanks Mathieu!
Typically these USB dongles are designed to appear as USB media devices (e.g. pseudo CD-ROM) and one has to mode switch it to a USB modem. Unfortunately I had a Huawei E1552/E1800 which required some USB mode switching magic, but to find this I first required internet connectivity. Fortunately I had a sacrificial laptop which I installed an old version of Windows XP which allowed me to then connect to the internet using the 3G USB dongle and I was able to then track down the appropriate runes. OK, I feel bad about installing Windows XP, but I was being pragmatic - I needed connectivity!
The procedure to get this device working on Ubuntu wasn't too bad. First I identified the USB dongle using lsusb to get the vendor and product IDs (12d1:1446):
Bus 002 Device 013: ID 12d1:1446 Huawei Technologies Co., Ltd. E1552/E1800 (HSPA modem)
Then I added the following runes to /etc/usb_modeswitch.conf -
DefaultVendor= 0x12d1
DefaultProduct=0x1446
TargetVendor= 0x12d1
TargetProductList="1001,1406,140b,140c,141b,14ac"
CheckSuccess=20
MessageContent="55534243123456780000000000000011060000000000000000000000000000"
..this appears in many forums on the internet, kudos to whoever figured this out.
Then I ran "sudo usb_modeswitch -c /etc/usb_modeswitch.conf" and this switched the dongle into:
Bus 002 Device 012: ID 12d1:14ac Huawei Technologies Co., Ltd.
..and I was then able to simply connect using network manager. Result!
** UPDATE **
Mathieu Trudel-Lapierre fixed this (9th Feb 2012) and now Ubuntu Precise works perfectly with the Huawei E1552/E1800. Thanks Mathieu!
Tuesday, 24 January 2012
open() using O_WRONLY | O_RDWR
One of the lesser known Linux features is that one can open a file with the flags O_WRONLY | O_RDWR. One requires read and write permission to perform the open(), however, the flags indicate that no reading or writing is to be done on the file descriptor. It is useful for operations such as ioctl() where we also want to ensure we don't actually do any reading or writing to a device. A bunch of utilities such as LILO seem to use this obscure feature.
LILO defines these flags as O_NOACCESS as follows:
..as in this example, you may find these flags more widely known as O_NOACCESS even though they are not defined in the standard fcntl.h headers.
Below is a very simple example of the use of O_WRONLY | O_RDWR:
It is a little arcane and not portable but also an interesting feature to know about.
LILO defines these flags as O_NOACCESS as follows:
#ifdef O_ACCMODE
# define O_NOACCESS O_ACCMODE
#else
/* open a file for "no access" */
# define O_NOACCESS 3
#endif
..as in this example, you may find these flags more widely known as O_NOACCESS even though they are not defined in the standard fcntl.h headers.
Below is a very simple example of the use of O_WRONLY | O_RDWR:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <fcntl.h>
int main(int argc, char **argv)
{
int fd;
struct winsize ws;
if ((fd = open("/dev/tty", O_WRONLY | O_RDWR)) < 0) {
perror("open /dev/tty failed");
exit(EXIT_FAILURE);
}
if (ioctl(fd, TIOCGWINSZ, &ws) == 0)
printf("%d x %d\n", ws.ws_row, ws.ws_col);
close(fd);
exit(EXIT_SUCCESS);
}
It is a little arcane and not portable but also an interesting feature to know about.
Friday, 20 January 2012
C ternary operator hack
Here is a simple bit of C that sets either x or y to value v depending on the value of c..
..but why not "improve" this by using the C ternary operator ? : as follows:
Now, how does this shape up when compiled on an x86 with gcc -O2 ? Well, the first example compiles down to a test and a branch where as the second example uses a conditional move instruction (cmove) and avoids the test and branch and is faster code. Result!
OK, so this isn't rocket science, but does show that a little bit of abuse of the ternary operator can save me a few cycles if the compiler is clued up to use cmove.
if (c)
x = v;
else
y = v;
..but why not "improve" this by using the C ternary operator ? : as follows:
*(c ? &x : &y) = v;
Now, how does this shape up when compiled on an x86 with gcc -O2 ? Well, the first example compiles down to a test and a branch where as the second example uses a conditional move instruction (cmove) and avoids the test and branch and is faster code. Result!
OK, so this isn't rocket science, but does show that a little bit of abuse of the ternary operator can save me a few cycles if the compiler is clued up to use cmove.
Tuesday, 17 January 2012
Improving Battery Life in Ubuntu Precise 12.04 LTS (part 2)
Last month I wrote about the investigations being undertaken to identify any suitable power savings for Ubuntu Precise 12.04 LTS. Armed with a suitably accurate 6.5 digit precision Fluke digital multimeter I worked my way through the Kernel Team Power Management Blueprint measuring many numerous configurations and ways to possibly save power.
A broad range of areas were examined, from kernel tweaks, hardware settings to disk wake-ups and application wakeup events.
Quite a handful of misbehaving applications have been identified ranging from frequent unnecessary wake-ups on poll() and select() calls to rather verbose logging of debug messages that stop the disk from going into power saving states.
We also managed to identify and remove pm-utils power.d scripts that didn't actually save any power and even consumed more power on newer Solid State Drives. By carefully analysing all the PowerTop recommendations we also identified a subset of device power management savings that are shown to be useful and save power across a wide range of machines. After crowd-source testing these tweaks we have now added them into pm-utils for Ubuntu Precise 12.04 LTS by default. I'm very grateful to the Ubuntu community for participating in the testing and feedback.
I've written a brief summary of all the test results, however, the full results can be found in the various subdirectories here. I've also written a very simple set of recommendations to help application developers avoid mistakes that lead to power wasting applications.
We've also set up a Power Management Wiki page that has links to the following:
* Identifying Power Sucking Applications
* Aggressive Link Power Management call for testing
* PCIe Active State Power Management call for testing (now complete)
* Updates to pm utils scripts call for testing (now complete)
..and probably the most useful:
* Power Saving Tweaks
The Power Saving Tweaks page lists a selection of tweaks that can be employed to save power on various machines. Unfortunately with some hardware these tweaks cause lock-ups or rendering bugs, so they cannot be rolled out by default unless we can find either a definitive list of the broken hardware or a large enough whitelist to enable these on a useful set of working hardware. Some of the tweaks cannot be rolled out for all machines as users want specific functionality enabled by default, for example, we need to enable Bluetooth for users with bluetooth keyboards and so it is up to the user to chose to disable Bluetooth to save 1-2 Watts of power.
I've also set-up a PPA with a few tools to help measure power and track down misbehaving wake-up events and CPU intensive applications. These tools don't replace tools like PowerTop and top, but do allow me to track trends on a system over a long running period. You may find these useful too.
We also have a Ubuntu Power Consumption Project set up to help us track bugs related to power consumption issues and regressions.
Last, but no way least, I'd like to thank Steve Langasek and Martin Pitt for all their help with the pm-utils and various fixes to power sucking applications.
A broad range of areas were examined, from kernel tweaks, hardware settings to disk wake-ups and application wakeup events.
Quite a handful of misbehaving applications have been identified ranging from frequent unnecessary wake-ups on poll() and select() calls to rather verbose logging of debug messages that stop the disk from going into power saving states.
We also managed to identify and remove pm-utils power.d scripts that didn't actually save any power and even consumed more power on newer Solid State Drives. By carefully analysing all the PowerTop recommendations we also identified a subset of device power management savings that are shown to be useful and save power across a wide range of machines. After crowd-source testing these tweaks we have now added them into pm-utils for Ubuntu Precise 12.04 LTS by default. I'm very grateful to the Ubuntu community for participating in the testing and feedback.
I've written a brief summary of all the test results, however, the full results can be found in the various subdirectories here. I've also written a very simple set of recommendations to help application developers avoid mistakes that lead to power wasting applications.
We've also set up a Power Management Wiki page that has links to the following:
* Identifying Power Sucking Applications
* Aggressive Link Power Management call for testing
* PCIe Active State Power Management call for testing (now complete)
* Updates to pm utils scripts call for testing (now complete)
..and probably the most useful:
* Power Saving Tweaks
The Power Saving Tweaks page lists a selection of tweaks that can be employed to save power on various machines. Unfortunately with some hardware these tweaks cause lock-ups or rendering bugs, so they cannot be rolled out by default unless we can find either a definitive list of the broken hardware or a large enough whitelist to enable these on a useful set of working hardware. Some of the tweaks cannot be rolled out for all machines as users want specific functionality enabled by default, for example, we need to enable Bluetooth for users with bluetooth keyboards and so it is up to the user to chose to disable Bluetooth to save 1-2 Watts of power.
I've also set-up a PPA with a few tools to help measure power and track down misbehaving wake-up events and CPU intensive applications. These tools don't replace tools like PowerTop and top, but do allow me to track trends on a system over a long running period. You may find these useful too.
We also have a Ubuntu Power Consumption Project set up to help us track bugs related to power consumption issues and regressions.
Last, but no way least, I'd like to thank Steve Langasek and Martin Pitt for all their help with the pm-utils and various fixes to power sucking applications.
Monday, 2 January 2012
Commodore 64 is 30
 | |
| The C64 boot screen (running in vice) |
The lack of a powerful BASIC interpreter directed my attention to learning 6502 assembler so I could start writing 3D wire frame vector graphics. I learned how to write cycle accurate timing code to drive the VIC II to make side borders disappear and with raster interrupts to make the the top and bottom borders disappear too. I also wedged in my own BASIC tokenizer and interpreter to extend the BASIC to provide better structured programming (while/wend, procedures, repeat/until) and sound, graphics and disk support - all this taught me how to structure large projects in assembler and how to write compact and efficient code.
I spent hours pouring over the disassembled C64 BASIC and Kernal ROMs and learned the art of reverse engineering from the object code. I figured out the tape format, analyzed the read/write characteristics of the tape drive head and re-wrote my own tape turbo loaders.
With the aid of an annotated ROM disassembly of the 1541 floppy drive I figured out how to write disk turbos and I hacked up my own fast formatting tools and my own file system.
By the time I was 17 I had acquired the the Super C Compiler and I learned how to write C on a system that had a 15 minute edit-compile-link-run turnaround cycle(!).
 |
| Elite on the C64. |
I was fortunate to have the time and energy and the right hardware available in my formative years, so I am grateful for Commodore for producing the quirky and hackable C64.
See also http://www.reghardware.com/2012/01/02/commodore_64_30_birthday