Sometimes the Scaling Maximum Frequency of a CPU is reduced below that of the possible top frequency and finding out why this is can be problematic. The limitation could have been imposed by:
* Thermal limits
* Hardware limitations (e.g. ACPI _PPC object).
* Program that wrote to a /sys/devices/cpu/cpu*/cpufreq/scaling_max_freq
Fortunately Thomas Renninger introduced /sys/devices/cpu*/cpufreq/bios_limit that exports to user space the BIOS limited maximum frequency for each CPU. This feature is available in Ubuntu Maverick 10.10 upwards.
So, if you have a machine that you believe should have CPUs running at a higher frequency, inspect the bios_limit files to see if the BIOS is mis-configured.
Friday, 30 September 2011
Tuesday, 27 September 2011
More interesting uses for SystemTap
Now and again while debugging systems I would like to be able to evaluate an ACPI method or object and see what it returns. To solve this problem in a generic way I put a little bit of effort today in developing a short SystemTap script that allows me to run acpi_evaluate_object() on a given named object and to dump out any returned data.
I've wrapped the gory details up into a small wrapper function called which is passed just the name of the object to evaluate and if necessary an acpi_object_list containing the arguments to be passed into a method call. For methods that don't require arguments, we end up with a simple call like the following:
acpi_eval("_BIF", NULL);
..and for more complex examples, with arguments, we have:
struct acpi_object_list arg_list;
union acpi_object args[1];
args[0].type = ACPI_TYPE_INTEGER;
args[0].integer.value = 1;
arg_list.count = 1;
arg_list.pointer = args;
acpi_eval("_WAK", &arg_list);
The script is designed to allow one to hack away and add in the calls to the objects that one requires to be evaluated, quick-n-dirty, but it does the job.
It was surprisingly easy to get this up and running with SystemTap once I had figured how to dump out the evalated objects to the tty - the script is fairly compact and the main bulk of the code is a terse error message table.
The script can be found it my SystemTap git repo: git://kernel.ubuntu.com/cking/systemtap-scripts.git
I've wrapped the gory details up into a small wrapper function called which is passed just the name of the object to evaluate and if necessary an acpi_object_list containing the arguments to be passed into a method call. For methods that don't require arguments, we end up with a simple call like the following:
acpi_eval("_BIF", NULL);
..and for more complex examples, with arguments, we have:
struct acpi_object_list arg_list;
union acpi_object args[1];
args[0].type = ACPI_TYPE_INTEGER;
args[0].integer.value = 1;
arg_list.count = 1;
arg_list.pointer = args;
acpi_eval("_WAK", &arg_list);
The script is designed to allow one to hack away and add in the calls to the objects that one requires to be evaluated, quick-n-dirty, but it does the job.
It was surprisingly easy to get this up and running with SystemTap once I had figured how to dump out the evalated objects to the tty - the script is fairly compact and the main bulk of the code is a terse error message table.
The script can be found it my SystemTap git repo: git://kernel.ubuntu.com/cking/systemtap-scripts.git
SystemTap print statements from "embedded C" functions.
SystemTap provides a flexible programming language to prototype debugging scripts very quickly. Sometimes however, one has to use "embedded C" functions in a SystemTap script to interface more deeply with the kernel.
Today I was writing a script to dump out ACPI object names and required some embedded C in my SystemTap script to walk the ACPI namespace and this required a C callback function. However, inside the C callback I wanted to print the handle and name of the ACPI object but couldn't figure out how to use the native SystemTap print() functions from within embedded C code. So I crufted up a simple "HelloWorld" SystemTap script and ran it with -k to keep the temporary sources and then had a look at the automagically generated code.
It appears that SystemTap converts the script print statements into _stp_printf() C calls, so I just plugged these into my C callback instead of using printk(). Now my output goes via the underlying SystemTap print mechanism and appears on the tty rather than going to the kernel log. Bit of a hack, but the result is easy to use. I wish it was documented though.
Here is a sample of the original script to illustrate the point:
Today I was writing a script to dump out ACPI object names and required some embedded C in my SystemTap script to walk the ACPI namespace and this required a C callback function. However, inside the C callback I wanted to print the handle and name of the ACPI object but couldn't figure out how to use the native SystemTap print() functions from within embedded C code. So I crufted up a simple "HelloWorld" SystemTap script and ran it with -k to keep the temporary sources and then had a look at the automagically generated code.
It appears that SystemTap converts the script print statements into _stp_printf() C calls, so I just plugged these into my C callback instead of using printk(). Now my output goes via the underlying SystemTap print mechanism and appears on the tty rather than going to the kernel log. Bit of a hack, but the result is easy to use. I wish it was documented though.
Here is a sample of the original script to illustrate the point:
%{
#include <acpi/acpi.h>
static acpi_status dump_name(acpi_handle handle, u32 lvl, void *context, void **rv)
{
struct acpi_buffer buffer = {ACPI_ALLOCATE_BUFFER};
int *count = (int*)context;
if (!ACPI_FAILURE(acpi_get_name(handle, ACPI_FULL_PATHNAME, &buffer))) {
_stp_printf(" %lx %s\n", handle, (char*)buffer.pointer);
kfree(buffer.pointer);
(*count)++;
}
return AE_OK;
}
...
%}
Monday, 26 September 2011
Mac Mini rebooting tweaks: setpci -s 0:1f.0 0xa4.b=0
Last night I was asked why Mac Minis require "setpci -s 0:1f.0 0xa4.b=0" to force the Mac to auto-reboot in the event of a power failure. Well, after a lot of Googling around I found that this setpci rune is quoted in a lot of places and at a guess probably originated from advice on the Mythical Beasts website. However, the explanation of what this rune actually did was distinctly lacking.
So, why is it required?
After some more searching around I found that device 00:1f.0 on the Mac Mini refers to:
00:1f.0 ISA bridge: Intel Corporation 82801GBM (ICH7-M) LPC Interface Bridge (rev 02)
..so my next step was to figure out why writing a zero byte to register 0xa4 on this device allows the Mac Mini to reboot. I located and download the ICH7 PDF from Intel and register at offset 0xa4 can be found in section 10.8.1.3. This refers to GEN_PMCON_3—General PM Configuration 3 Register. Even though the setpci command is clearing this whole register, I suspect we are just interested in clearing bit zero. The PDF states:
"AFTERG3_EN — R/W. This bit determines what state to go to when power is re-applied after a power failure (G3 state). This bit is in the RTC well and is not cleared by any type of reset except writes to CF9h or RTCRST#.
0 = System will return to S0 state (boot) after power is re-applied.
1 = System will return to the S5 state (except if it was in S4, in which case it will return to S4). In the S5 state, the only enabled wake event is the Power Button or any enabled wake event that was preserved through the power failure."
So, it looks like the "setpci -s 0:1f.0 0xa4.b=0" magic is just to return to a S0 (boot state) after power is re-applied after a power failure. All is explained, so not so magical after all.
So, why is it required?
After some more searching around I found that device 00:1f.0 on the Mac Mini refers to:
00:1f.0 ISA bridge: Intel Corporation 82801GBM (ICH7-M) LPC Interface Bridge (rev 02)
..so my next step was to figure out why writing a zero byte to register 0xa4 on this device allows the Mac Mini to reboot. I located and download the ICH7 PDF from Intel and register at offset 0xa4 can be found in section 10.8.1.3. This refers to GEN_PMCON_3—General PM Configuration 3 Register. Even though the setpci command is clearing this whole register, I suspect we are just interested in clearing bit zero. The PDF states:
"AFTERG3_EN — R/W. This bit determines what state to go to when power is re-applied after a power failure (G3 state). This bit is in the RTC well and is not cleared by any type of reset except writes to CF9h or RTCRST#.
0 = System will return to S0 state (boot) after power is re-applied.
1 = System will return to the S5 state (except if it was in S4, in which case it will return to S4). In the S5 state, the only enabled wake event is the Power Button or any enabled wake event that was preserved through the power failure."
So, it looks like the "setpci -s 0:1f.0 0xa4.b=0" magic is just to return to a S0 (boot state) after power is re-applied after a power failure. All is explained, so not so magical after all.
Sunday, 25 September 2011
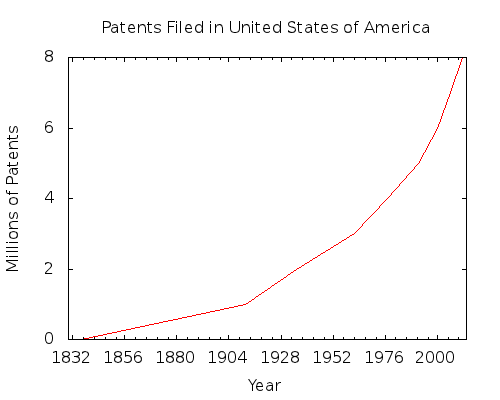
Exponential Growth of Patents
The United States Patent and Trademark Office (USPTO) recently publish an interesting article about the millions of patents issued by the United States of America. Using the current numbering system, patent #1 was issued in 1836 and patent #8,000,000 was recently issued in August this year. I plotted issue date against patent number and lo and behold we get exponential growth of patents since the turn of the 20th century:
 At this rate, we will see 8 million more patents issued by the end of 2016. Intellectual property is abundant, perhaps too much so. Are all these patents totally valid? Is there any kind of quality control being applied? Personally, I doubt it. I don't want to be alarmist, but I really think this is getting totally out of control.
At this rate, we will see 8 million more patents issued by the end of 2016. Intellectual property is abundant, perhaps too much so. Are all these patents totally valid? Is there any kind of quality control being applied? Personally, I doubt it. I don't want to be alarmist, but I really think this is getting totally out of control.
Patents are used as trading tokens as big businesses wage war against each other. Companies are loading their war-chests with patent portfolios to block rivals from bringing to market innovative new products which leads to a product monoculture. More perversely, patents are being used so sue users of technology rather than manufacturers. Ultimately the consumer is the loser and patent lawyers and big business are the winners - that's the price for patents protecting innovation.
Patents are used as trading tokens as big businesses wage war against each other. Companies are loading their war-chests with patent portfolios to block rivals from bringing to market innovative new products which leads to a product monoculture. More perversely, patents are being used so sue users of technology rather than manufacturers. Ultimately the consumer is the loser and patent lawyers and big business are the winners - that's the price for patents protecting innovation.
Thursday, 22 September 2011
Tweaking partitions for optimal use of the HDD
By default Ubuntu is installed with the root filesystem at the start of the disk drive and with swap right at the end. If one analyses the read/write performance of a hard disk drive (HDD) one will quickly spot that the I/O rates differ depending on the physical location of the data.
From the relatively small sample of laptop and desktop drives that I've looked at it seems that reads from the logical start of the drive are fastest and drop off down to roughly half that rate near the end of the drive. The rate is higher for data on the outer tracks (because there are more data sectors) and lower toward the inner tracks (fewer data sectors).
Since my new 7200rpm 250GB drive performs fastest at the lowest logical block locations, it makes sense to construct my partitions to utilise this. For my configuration, I want to load my kernels and initrd in quickly and be able to swap and hibernate fairly quickly too. Next I want applications to load quickly, and my user data (such as mp3s, cached Email, etc) I care less about for performance. So, with these constraints, I created separate partitions in this order:
1st /boot (ext4), 2nd swap, 3rd / (ext4) and 4th /home (ext4).
Some quick'n'dirty write benchmarks show me that:
..so this should make booting, swapping and hibernating just slightly faster. Over the lifetime of the drive the random file writes and deletions in /home won't cause /boot new kernels and initrd images to be fragmented because the are on separate partitions. Also I can avoid over-writing all my user data in /home if I do a clean installation of Ubuntu into /boot and / at a later date.
From the relatively small sample of laptop and desktop drives that I've looked at it seems that reads from the logical start of the drive are fastest and drop off down to roughly half that rate near the end of the drive. The rate is higher for data on the outer tracks (because there are more data sectors) and lower toward the inner tracks (fewer data sectors).
Since my new 7200rpm 250GB drive performs fastest at the lowest logical block locations, it makes sense to construct my partitions to utilise this. For my configuration, I want to load my kernels and initrd in quickly and be able to swap and hibernate fairly quickly too. Next I want applications to load quickly, and my user data (such as mp3s, cached Email, etc) I care less about for performance. So, with these constraints, I created separate partitions in this order:
1st /boot (ext4), 2nd swap, 3rd / (ext4) and 4th /home (ext4).
Some quick'n'dirty write benchmarks show me that:
/boot : 84.74 MB/s
swap : 84.44 MB/s
/ : 82.26 MB/s
/home : 73.30 MB/s..so this should make booting, swapping and hibernating just slightly faster. Over the lifetime of the drive the random file writes and deletions in /home won't cause /boot new kernels and initrd images to be fragmented because the are on separate partitions. Also I can avoid over-writing all my user data in /home if I do a clean installation of Ubuntu into /boot and / at a later date.
Sunday, 18 September 2011
Laptop HDD woes
 I do quite a bit of international travelling and my old klunky Lenovo 3000N200 takes a few knocks and consequently I've had to purchase my 2nd HDD for this laptop in the past 3.5 years.
I do quite a bit of international travelling and my old klunky Lenovo 3000N200 takes a few knocks and consequently I've had to purchase my 2nd HDD for this laptop in the past 3.5 years.{kind=link}
Last week my laptop hung for tens of seconds while logging in - and once more again today. Looking at the kernel log I was able to see repeated time-outs on read errors which was a little alarming. The palimpsest utility showed that I had a few bad sectors and there were a few pending to be remapped. I had a quick look at the S.M.A.R.T. data using:
sudo smartctl -d ata -a /dev/sda
..and saw that I'd got 5311 hours of use out of the drive and considering I bought it about 400 days ago works out to be ~13.25 hours of usage per day on average. Peeking at /sys/fs/ext4/sda*/lifetime_write_kbytes it appeared I had written 1.4TB of data, which works out to be 0.27GB of writes per hour of use on average - which sounds fair as my laptop is mainly used for Web, Email and the occasional bit of compilation (as I do most kernel builds on large servers).
So what do I replace it with? Well, being a cheapskate, I did not want to splash out on an expensive SSD on this relatively old laptop (which I will palm off to my kids fairly soon), so I went for an spinny disk upgrade. My original drive was a 160GB 5400rpm WD1600BEVT - this time I spent an extra £5 and got a 2500GB 7200rpm WD2500BEKT with double the internal cache and improved read performance - the postage was free from dabs.com so double win.
Saturday, 17 September 2011
Formatting Source Code in Blogs
At last, I've found a useful tool for producing correctly formatted source code for the inclusion into my blog.
Thanks to codeformatter, one can paste in source, select the appropriate formatting style options and produce blog formatted output to paste into one's blog articles! Easy!
Thanks to codeformatter, one can paste in source, select the appropriate formatting style options and produce blog formatted output to paste into one's blog articles! Easy!
Reading MTRRs via the MTRRIOC_GET_ENTRY ioctl()
The MTRRIOC_GET_ENTRY ioctl() is a useful but under-used ioctl() for reading the MTRR configuration from /proc/mtrr. Instead of having to read and parse /proc/mtrr, the ioctl() provides a simple interface to easily fetch each MTRR.
A struct mtrr_gentry is passed to the ioctl() with the regnum member set to the MTRR register one wants to read. After a successful ioctl() call, size member of struct mtrr_gentry is less than 1 if the MTRR is disabled, otherwise it is populated with the MTRR register configuration.
Below is an example showing how to use MTRRIOC_GET_ENTRY:
The downside to using MTRRIOC_GET_ENTRY is that MTRR base addresses > 4GB get returned as zero, which is a known "feature" of this interface - the offending code in mtrr_ioctl() in arch/x86/kernel/cpu/mtrr/if.c is as follows:
..clearly showing that gentry.base, .size and .type are set to zero for entries > 4GB.
A struct mtrr_gentry is passed to the ioctl() with the regnum member set to the MTRR register one wants to read. After a successful ioctl() call, size member of struct mtrr_gentry is less than 1 if the MTRR is disabled, otherwise it is populated with the MTRR register configuration.
Below is an example showing how to use MTRRIOC_GET_ENTRY:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ioctl.h>
#include <asm/mtrr.h>
#include <fcntl.h>
#define LONGSZ ((int)(sizeof(long)<<1))
int main(int argc, char *argv[])
{
struct mtrr_gentry gentry;
int fd;
static char *mtrr_type[] = {
"Uncachable",
"Write Combining",
"Unknown",
"Unknown",
"Write Through",
"Write Protect",
"Write Back"
};
if ((fd = open("/proc/mtrr", O_RDONLY, 0)) < 0) {
fprintf(stderr, "Cannot open /proc/mtrr!\n");
exit(EXIT_FAILURE);
}
memset(&gentry, 0, sizeof(gentry));
while (!ioctl(fd, MTRRIOC_GET_ENTRY, &gentry)) {
if (gentry.size < 1)
printf("%u: Disabled\n", gentry.regnum);
else
printf("%u: 0x%*.*lx..0x%*.*lx %s\n", gentry.regnum,
LONGSZ, LONGSZ, gentry.base,
LONGSZ, LONGSZ, gentry.base + gentry.size,
mtrr_type[gentry.type]);
gentry.regnum++;
}
close(fd);
exit(EXIT_SUCCESS);
}
The downside to using MTRRIOC_GET_ENTRY is that MTRR base addresses > 4GB get returned as zero, which is a known "feature" of this interface - the offending code in mtrr_ioctl() in arch/x86/kernel/cpu/mtrr/if.c is as follows:
/* Hide entries that go above 4GB */
if (gentry.base + size - 1 >= (1UL << (8 * sizeof(gentry.size) - PAGE_SHIFT))
|| size >= (1UL << (8 * sizeof(gentry.size) - PAGE_SHIFT)))
gentry.base = gentry.size = gentry.type = 0;
else {
gentry.base <<= PAGE_SHIFT;
gentry.size = size << PAGE_SHIFT;
gentry.type = type;
}
..clearly showing that gentry.base, .size and .type are set to zero for entries > 4GB.
Thursday, 8 September 2011
Firmware Test Suite presentation at Linux Plumbers Conference
This week I'm attending the Linux Plumbers Conference in Santa Rosa, CA. Yesterday I gave a brief presentation of the Firmware Test Suite in the Development Tools, and for reference, I've uploaded the slides here.
Subscribe to:
Posts (Atom)